



CCNAの合格点は? 試験改定後の傾向や勉強方法を解説
2022.04.27
![]()

世の中には、実に多くの便利なサービスがあります。インターネットやスマートフォンからさまざまな情報を入手することが可能ですが、それらのサービスの多くはデータベースを活用しています。
今回の記事では、そんなデータベースとつながりが深いSQLという言語について、基本的な使い方や、SQLを使用するエンジニアに就職するうえで有益な情報をまとめています。
SQLは楽しく、仕事にすることもできる大変優れた言語なので、ぜひ今回の記事を参考に習得して、就活などに役立ててください。
目次
開くあなたにはどれが向いてる? 今すぐエンジニア診断してみよう
「エンジニアになってIT業界で働きたい」
「エンジニアに興味はあるけど、種類が多すぎて自分に向いてる職種がわからない」
そんな悩みを解決するのが、「エンジニア診断ツール」です。
「エンジニア診断」はたった12の質問に答えるだけで、あなたに向いているエンジニアを診断。
診断結果には仕事内容の概要も掲載しているので、自分に合ったエンジニアについて詳しく知って、エンジニア就職に一歩近づきましょう。
SQLは、データベース(RDBMS)を操作するための言語です。データベースに管理されているデータを検索したり、追加や削除といった操作を行います。国際標準化されている言語なので、多くのデータベースシステムで使うことができます。
人間が手作業で行う以外に、ソフトウェアのプログラムがデータベースに対して操作を行う場合にも、多くの場合はSQLが使われます。SQLは、データベースを操作する基本的な知識でもあり、国家資格の基本情報技術者試験の範囲にも含まれています。
基本情報技術者試験についての詳しい情報は、以下の記事にまとめてあるので、興味のある方はご覧ください。
関連記事:基本情報技術者試験の攻略ガイド|日程から勉強方法まで完全網羅
SQLはプログラムから使われることもありますが、プログラミング言語ではありません。一般的なプログラミング言語が、OS(オペレーティングシステム)上で動くアプリケーションを構築するのに対して、SQLはデータベースシステムに対してのみ操作を行うことができる限定的な言語となっています。
SQLは蓄積したデータを効率よく扱うことに特化した言語で、多くのデータを扱うサービスやアプリケーションで利用されています。アプリケーションの動きの部分はプログラミング言語で作り、データベースとやり取りする部分のプログラムにはSQLを使うといった手法が一般的です。
最初にデータベースを作るときや、データを手作業で調べる際などには、データベースに直接接続してSQLを使用します。この方法では一つずつSQLを実行して、一つずつ結果を取得します。
通常のソフトウェアの場合は、プログラムからデータベースへ接続して、SQLを使用して結果を得るという方法がとられます。データベースから取得したデータに応じて画面に表示する内容を変化させたり、ユーザーが入力した内容をデータベースに登録するなど、プログラムの処理と合わせることで、複雑な処理を行うことが可能となります。
使用するデータベースの種類によって手順は異なりますが、ほとんどの場合どちらの方法も行えるようになっています。
自分の適性が分かる!今すぐエンジニア診断してみよう
「エンジニアに興味はあるけど、種類が多すぎて自分に向いてる職種がわからない」
そんな悩みを解決するのが、「エンジニア診断ツール」です。
エンジニア診断ツールの特徴
「エンジニア診断」はたった12の質問に答えるだけで、あなたに向いているエンジニアを診断。
診断結果には仕事内容の概要も掲載しているので、自分に合ったエンジニアについて詳しく知って、エンジニア就職に一歩近づきましょう。
SQLで操作するデータベースは、データを蓄積して管理することに特化したシステムで、検索などが便利なように設計されています。データベースは一般的なソフトウェアとして提供されていて、多くはSQLで操作することができます。
世の中にある多くのソフトウェアはデータベースを活用して構築されていますが、すべてのソフトウェアにデータベースとSQLが用いられているわけではありません。ここでは、どのようなときにデータベースが利用されているのかを具体的に紹介します。
Amazonのようなネットショッピングサイト(EC)では、商品の情報や取引情報の取り扱いにデータベースは欠かせません。動画サイトや検索エンジンなどでも、利用している側は意識することは少ないかもしれませんが、データの管理にデータベースを使っています。
インターネット上で普段私たちが使うサービスやアプリなどの多くで、データベースが利用されています。
さまざまなサービスを利用する私たちの代わりに、プログラムがデータベースに対してSQLを実行して必要なデータを操作し、データベース操作の結果を私たちに返してくれることで、一つのサービスが提供できています。
データを扱うすべてのシステムが、データベースを使っているわけではありません。データベースは、大きなデータがシステムの中心に位置していて、そのデータを多くの利用者が使うという形だと非常に有用なシステムですが、個別の環境で動くソフトウェアなどでは小回りが利かず、デメリットの方が大きくなるケースもあります。
たとえばゲームのような場合だと、実行されるゲーム機や個別のパソコンなどにデータが必要なので、データベースを使うとシステムが煩雑になることもあり、データを独自の形式で運用することがあります。
そういった場合でも、たとえばランキング情報のような中央にデータを集める必要がある部分では、インターネット上のサーバーにデータベースを準備して、SQLで管理を行うといった使い分けも行われます。
30秒で結果がわかる! エンジニア診断を無料で受けよう
「エンジニア診断ツール」を使うと、12の質問に答えるだけで、8種類のエンジニアの中から一番自分に向いているエンジニアがわかります。
さらに、「エンジニア診断」は無料で受けられて、診断結果には向いているエンジニアの仕事内容が記載されているので、自分の適性をその場で理解することが可能です。
「エンジニア診断」を活用して、エンジニア就職に一歩近づきましょう。
データベースシステムには、さまざまな種類のソフトウェアが存在しています。データベースシステムの中枢にあるデータ管理基盤を「データベースエンジン」と呼びます。
同じデータベースシステムという種類のソフトウェアでも、データベースエンジンごとに特徴があり、IT業界のソフトウェア開発現場では、利用シーンに応じて適切なデータベースエンジンが選択されます。
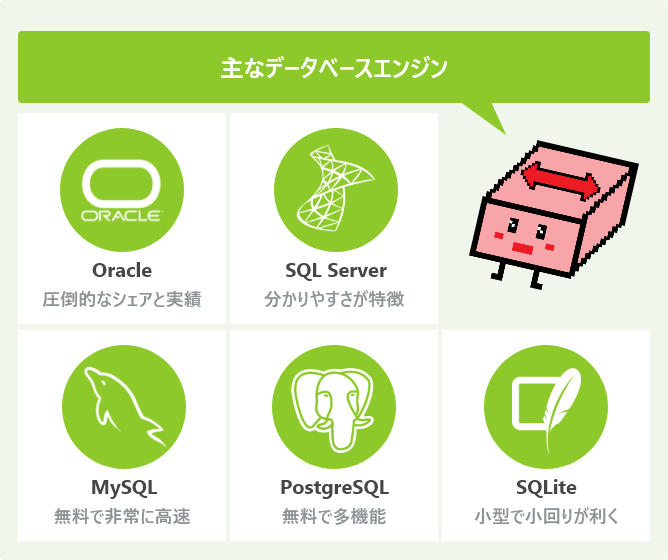
ここでは、IT業界の現場で利用されることが多いデータベースエンジンについて、いくつか主要なものを紹介します。
「Oracle」は、データベース界の巨人とも言われるほど、長い間シェアNo.1を維持し続けているデータベースエンジンです。圧倒的なシェアと実績によって、導入する際の安心感もあり、また利用できる環境も多いため、さらに導入実績が増え続けています。開発する際に便利な機能も多く、導入後の安定感も素晴らしいデータベースです。
ただし、唯一の欠点は有料であることです。データベースエンジンには無料のものもあり、初期投資を抑えたい開発案件などでは、予算の関係でOracleの導入を見送ることもあります。
「SQL Server」は、Windowsを提供している会社として広く知られているMicrosoft社がリリースしているデータベースエンジンです。シェアとしてはOracleに続いて2位となっていますが、最近の開発現場では比較的出会うことが少ないかもしれません。Oracle同様にSQL Serverも有料で、そのうえOSのWindowsも有料なため、データベースシステムとしては初期投資に最も費用が掛かります。
管理面については、古くからManagement StudioのようなGUIで簡単に操作できるツールも多く提供されていて、マニュアルが不要なほどの分かりやすさが特徴です。
「MySQL」は、非常に高速なデータベースとして有名で、特に検索性能が重要視されるようなシステムで導入されやすい傾向にあります。
多くのデータが集まっていくと、検索などの処理速度が徐々に遅くなっていきます。できるだけ速く動くデータベースを選びたいため、速度に絶対的な信頼のあるMySQLが、OracleやSQL Serverといった大御所を抑えて導入されることも多いです。
MySQLは無料のデータベースシステムではありますが、権利表記などが必要な場合もあり、商用サービスで使う場合などでは特にライセンス面での注意が必要となります。
無料で多機能なデータベースとして、開発現場で採用されることが多いのが「PostgreSQL」です。MySQLのようにライセンスの心配もなく、広く自由に使うことができることもあって、初期投資を抑えたいソフトウェア開発の現場では、頻繁に候補として名前が挙がります。
LinuxだけでなくWindowsでも利用可能で、比較的容易に導入作業も行うこともできることもあり、本番はLinuxのサーバーで動かす予定でも、開発環境は仮のWindowsのサーバーで行うという場合もあります。
お手軽なのに機能満載で無料なので個人から企業まで広く利用されています。特にデータベースの勉強をしたり、何かの検証をするための環境として非常に便利です。
データベースシステムはサーバー上で動かすのが一般的ですが、最近のスマートフォンの流通に合わせて、もっと小型で小回りの利くデータベースが求められるようになりました。
「SQLite」は、そういった個別の環境におけるデータ管理をSQLで行うことができるようにしたデータベースです。独自形式のような可用性を持ったSQLiteのデータベースは、単純なファイルとして存在しているだけで、プログラマーが容易に扱うことができるようになっています。
スマートフォンアプリなどでは、データ管理面の開発期間を抑えるためにSQLiteを導入することも多くあります。SQLiteのおかげで、短い期間で多彩なデータ活用機能を備えたソフトウェアを容易に構築できます。
エンジニア診断を受けて最初の1歩を踏み出そう!
エンジニアになるかどうか悩んでいる人は、まず「エンジニア診断ツール」を活用するのがおすすめです。
「エンジニア診断」を使うと、どのエンジニアに自分が向いているのか、簡単に理解することができます。約30秒で診断できるので、気軽に利用してみてください。
エンジニア診断ツールでわかること
SQLで操作するデータベースにはさまざまな種類がありますが、それらには共通した構造があります。その構造を理解することで、データベースの多くを使うことができます。
最も身近なデータを扱うソフトウェアといえば、エクセルのような表計算ソフトが挙げられるでしょう。表計算ソフトは、縦と横に自由なレイアウトでデータを入力して管理できるため、多くの人に利用されています。
ここではデータベースの構造を理解しやすいように、エクセルのイメージと照らし合わせながら、基本構造について紹介していきます。
データベースの「テーブル」は、エクセルのシートのようなもので、データの種類などで一括りにまとめた表のことです。通常データベースにはデータの役割ごとに複数のテーブルが定義され、その中にそれぞれのデータが蓄積されていきます。テーブルの構造は自由に設計できます。
エクセルにシートがなければデータを記録できないのと同じように、データベースにもテーブルがなければデータを蓄積できません。データベースにとってテーブルは、データ管理の基本構造といえます。
また、同じテーブルという構造でありながらも、システム内での役割が異なる抽象的な概念が用いられることも多く、ここではその代表的なものを以下に紹介します。
データの変動が少なく、特に他のデータに参照される台帳のような役割を果たすテーブルを「マスターテーブル」と呼びます。
マスターテーブルには、利用者がデータを作るのではなく、システム管理者がサービス運営前にあらかじめデータを入れておくこともあります。
基幹システムなどでは、マスターテーブルのデータをソフトウェア上で管理する「マスター管理」機能を設けることもあります。この中には、利用者マスターのような比較的変動が多いものから、税率などのようにほとんど変動しないものもあります。システムに影響するデータに変更があった場合も、あらかじめデータベースで管理しておくことで、プログラムなどのシステム改修をできる限り回避します。
増え続ける一般的なデータを扱うテーブルを「トランザクションテーブル」と呼びます。ソフトウェア開発現場では、一般的に略して「トラン」と呼ばれます。マスター以外は基本的にはトランザクションテーブルなので、あえて明示的に呼ばない場合もあります。
長く運用しているシステムが遅くなる原因の一つに、トランザクションテーブルの総データ量が増えたことによるパフォーマンス低下が挙げられます。データ量が増えてくると、それだけ検索などに時間がかかるようになり、複雑なデータ操作では乗算的に速度低下を引き起こすようになります。
大量の蓄積データを効率よく扱うために優秀なSQLを組み立てるのは、エンジニアの重大な役目です。
データベースのテーブルの中身も、エクセルと同じような構造をしています。エクセルの列や行と対応するように、データベースにはカラム(列)とレコード(行)があり、目的に合わせて必要なカラムを設けるのも、エクセルと同じイメージです。
データベースの定義は厳密で、数値を扱うカラムには数値しか入れることができません。同じ種類のデータに制限することで、より効率的なデータ操作を行うことができるようになっています。
行であるレコードはロウ(Row)と表現される場合もありますが、データベースの構造的な話題のときなどに使用されることが多く、ソフトウェア開発の現場ではレコードと表現されることのほうが一般的です。
データベースのテーブルを操作するには、DDL(Data Definition Language)と呼ばれるSQLを利用します。DDLでは、テーブルの作成や削除などといった、テーブルの定義に関する操作を行うことができます。
データベースにデータを蓄積するためには必ずテーブルが必要になるため、どのようなシステムでも最低一度はこのDDLに関するSQLを実行します。
使用頻度は少ないですが、必ず必要になるSQLなので、最低限の知識は身につけましょう。
| 構文 | 操作内容 |
|---|---|
| CREATE | テーブル作成 |
| ALTER | テーブル修正 |
| DROP | テーブル削除 |
データベースにテーブルを作成する最も単純なSQLは以下のようなものになります。
| [例] CREATE TABLE m_user; |
|---|
[結果]
「m_user」という名前のテーブルを作成する。
この例で作成されたテーブルは、まだカラムの定義がない状態です。以下のように同時にカラムの定義まで行うこともできます。
| [例] CREATE TABLE m_user (int id, name varchar(32)); |
|---|
[結果]
「m_user」という名前のテーブルを作成して、テーブル内にint型の「id」とvarchar型で長さ32の「name」というカラムを定義する。
カラムにはそれぞれ「データ型」というものがあり、「整数」や「文字列」などデータベースにはさまざまなデータ型が用意されています。「int型」は整数値を扱う型で、「varchar型」は文字列を扱う型で、括弧で長さを指定しています。
CREATE TABLEの構文は、以下のようになっています。
| [例] CREATE TABLE テーブル名 ( カラム1 カラム1の型名, カラム2 カラム2の型名, … ); |
|---|
「CREATE TABLE」に続けて作成するテーブル名を指定して、テーブル名の後ろに括弧で括って定義するカラムを列挙した形式になっています。カラムを複数定義する場合は、間を「,(カンマ)」で区切ります。SQLの最後には「;(セミコロン)」を付ける決まりです。
「CREATE TABLE」には、これ以外にも指定できるオプションもありますが、ここでは簡単な例のみを紹介しています。もっと詳しく知りたい方は、各データベースエンジンのマニュアルなどをご確認ください。
作成されるテーブルのイメージとしては以下のような形です。実際のデータは作成されるまでは空ですが、ここでは分かりやすく3件ほどデータがある状態で紹介しています。
[m_userのイメージ]
| id | name |
| 1 | 山田太郎 |
| 2 | 佐藤花子 |
| 3 | 高橋一郎 |
作成したテーブルを後から修正する際には、「ALTER」というSQLを使用します。ALTERを使うことで、カラムの追加や名前の変更などさまざまなことができます。ここではカラムの追加を例に紹介します。
| [例] ALTER TABLE m_user Add value int; |
|---|
[結果]
「m_user」テーブルに、新しいカラムとしてint型の「value」を追加する。
「ALTER TABLE」で操作したいテーブル名を指定した後、カラム追加を意味する「Add」を指定して、続けて追加するカラムの定義を記載した形になっています。
ALTER TABLEの構文は、以下のようになっています。
| [例] ALTER TABLE テーブル名 操作 修正内容; |
|---|
操作の部分に指定できるものとしては、以下のようなものがあります。
修正内容の部分は、指定した操作に対応して変化します。
このSQLの実行によって修正された「m_user」の想定イメージは以下のようなものとなります。新しい「value」の項目が右端に追加されています。
[m_userのイメージ]
| id | name | value |
| 1 | 山田太郎 | 80 |
|---|---|---|
| 2 | 佐藤花子 | 75 |
| 3 | 高橋一郎 | 92 |
作成したテーブルが後から不要になった場合などは、「DROP」というSQLを使用して削除します。DROP操作は元に戻すことができないので、実行する際には注意しましょう。
| [例] DROP TABLE m_user; |
|---|
[結果]
「m_user」テーブルを削除する。
「DROP TABLE」は非常に危険なSQLなため、ソフトウェア開発の現場では、実際に使われている環境ではほとんど実施されることがありません。不要となったテーブルについては、削除せずに残しておくのが一般的です。データベースというシステムは、使わないテーブルが残っていても、他のテーブルの検索などにはほとんど影響しない構造となっています。
SQLでデータを扱うには、DML(Data Manipulation Language)と呼ばれるSQLを利用します。最も頻繁に使われるSQLで、データベース分野におけるエンジニアの知識や経験が問われます。
SQLは、ここで紹介するような基本的なものを組み合わせて、さまざまなことをする言語です。工夫の仕方は無限大で、実行結果が同じ場合でも、人によってまったく異なるSQLであることも珍しくありません。
| 構文 | 操作内容 |
|---|---|
| SELECT | データ取得 |
| INSERT | データ挿入 |
| UPDATE | データ更新 |
| DELETE | データ削除 |
データを取得する「SELECT」は、最も使用されるSQLの一つです。データベースのテーブルに蓄積されているデータを取得するSQLで、取得する際に絞り込み(検索)条件を指定できます。
データベースの検索機能は非常に優れていて、大抵の場合で独自にデータ検索プログラムを作るよりも圧倒的に素早くデータの抽出が行えるため、幅広い分野のソフトウェアでデータベースが活用されています。
データベースを扱うエンジニアにとって、優秀なSELECT文を作成できることが非常に重要です。今回紹介するのは基本的なことだけですが、これらを組み合わせていくことで、複雑で高度な検索をするSQLを作っていくことになるので、しっかりと理解していきましょう。
最初に最も単純なSELECT構文から紹介します。サンプルテーブルとして、テーブルの操作の項で定義した「m_user」を使って、実行結果のイメージを合わせて確認していきます。
| [例] SELECT * from m_user; |
|---|
[実行結果]
| id | name | value |
| 1 | 山田太郎 | 80 |
| 2 | 佐藤花子 | 75 |
| 3 | 高橋一郎 | 92 |
「SELECT」に続けて指定されている「*」は「すべてのカラムを取得する」という意味です。「from」によって対象のテーブルを指定しています。このSQLでは、他に何も条件などが指定されていないため、fromで指定したテーブル内の全データ取得という結果になります。
今度は絞り込みを指定したSELECT文の例を見ていきましょう。
| [例] SELECT * from m_user where id = 2; |
|---|
[実行結果]
| id | name | value |
| 2 | 佐藤花子 | 75 |
先ほどの例に加えて、「where」という条件指定句が追加されています。「where」に続けて条件の 「id = 2」を指定したことにより、実行結果ではその条件を満たすものだけが返却されています。
条件指定には複数の条件も記載でき、それらの条件を「AND」や「OR」といった論理条件式を使って、さらに複雑な条件設定できるようになっています。比較演算子には等価を意味する「=(イコール)」以外に、数値が間にあるかを判定する「between」や、文字列が含まれるかを判定する「like」など種類が多くあり、このwhere句の指定方法の工夫は、エンジニアの腕の見せ所でもあります。
最後に取得するカラムを指定するパターンを紹介します。
| [例] SELECT * from m_user where id = 2; |
|---|
[実行結果]
| name |
| 佐藤花子 |
「SELECT」の後ろに指定していた「*」の代わりに「name」というカラムを指定しています。これにより、実行結果で指定したカラムの「name」だけが返ってくるようになっています。
このカラム指定は、一見すると不便になっているだけのようにも見えるかもしれませんが、実はソフトウェア開発現場では非常に重要です。カラムを多く指定すると、それだけデータベースエンジンに負荷がかかり速度も低下します。高速な処理のためには、不要なカラムは極力取得しないように心掛ける必要があります。
データを挿入するには、「INSERT」を使います。データベースはデータを蓄積していくほど価値が高まるものでもあるので、データを生み出すINSERTは、データ抽出をするSELECTと同じくらいに重要といってもいいでしょう。
システムに対してデータを登録するよりも、データを閲覧することの方が多いため、SQLとしての使用頻度については、SELECTよりも低くなるのが一般的です。登録の際はINSERTが一回だけ行われ、そのデータを閲覧するたびにSELECTが実行されているイメージになります。
INSERTは重要ではありますが、SQLとしては単純で工夫できることも少なく、一度覚えてしまえば後はその繰り返しとなるので、最初に正しい文法をしっかり覚えましょう。
データの挿入を行うINSERTの基本的な構文は以下のようになります。INSERTの結果にはSQLとしては成功か失敗しかありませんが、イメージしやすいように、実行後のテーブルの状態を以下に紹介します。
| [例] INSERT INTO m_user(id, name, value) values (4, ‘田中夏子’, 65) |
|---|
[実行後のテーブルの状態]
| id | name | value |
| 1 | 山田太郎 | 80 |
| 2 | 佐藤花子 | 75 |
| 3 | 高橋一郎 | 92 |
| 4 | 田中夏子 | 65 |
|---|
「INSERT」によって、「id=4」のデータが挿入されています。
「INSERT」構文は、テーブルを指定した後に括弧でカラムを列挙して、「values」の後ろに対応したカラムのデータを指定します。指定しなかったカラムには、テーブル定義で定められた標準の値(0やnullなど)が埋められます。
一般的なシステムでは、データは1件ずつ登録することが多いですが、INSERT文では複数のデータを一度に作成したり、「values」の指定の代わりにSELECT文を指定して検索結果をまとめて登録することもできます。
テーブル定義のカラムの並びでデータを指定する場合は、カラムの列挙は省略することができます。以下の例では、カラムの指定を省略しています。
| [例] INSERT INTO m_user values (4, ‘田中夏子’, 65) |
|---|
実行結果は省略していない場合と同じになります。
「INSERT」の後ろに「INTO」を付けて紹介してきていますが、INTOは省略できる場合があります。ほとんどのデータベースエンジンでは、INTOがなくても正しく実行されますが、Oracleでは省略できません。
このようなデータベースエンジンによる文法の違いなどを、IT業界内では「方言」といったりします。INSERTについては、省略できずエラーとなってしまうデータベースエンジンがあるので、最初からINSERT INTOで覚えてしまうことをオススメします。
「UPDATE」はデータを更新するSQLです。データベースを使ったシステムのデータ登録機能は、利用者が間違いを登録することを想定して、ほとんどの場合データの修正機能を設けます。データを修正する機能ではUPDATE文が使われます。
過去のデータ履歴を閲覧するような機能を提供する場合は、修正前の状態も保持する必要があるため、UPDATEではなくINSERTして新たにデータを登録して、それらを並列に管理するような設計が行われることもあります。
SQLのUPDATE文は、基本はすべてのデータを対象とするもので、条件を付けることで対象を絞り込みます。条件をつけ忘れてしまうと、すべてのデータが同じ値になってしまうことになるので注意しましょう。
ここでは最も頻繁に行う、一つのデータだけを更新するSQLを紹介します。UPDATEもINSERTと同じように、実行結果には成功と失敗しかありませんが、ここでは説明のため実行後のテーブルの状態を以下に紹介します。
| [例] UPDATE m_user set name=’高橋二郎’, value=100 where id = 3; |
|---|
[実行後のテーブルの状態]
| id | name | value |
| 1 | 山田太郎 | 80 |
| 2 | 佐藤花子 | 75 |
| 3 | 高橋二郎 | 100 |
|---|---|---|
| 4 | 田中夏子 | 65 |
UPDATE文では、テーブルを指定した後に「set」と続けて、その後ろに更新する内容を記載します。絞り込み条件の「where」は省略が可能です。
手作業でUPDATEのSQLを実行する場合は、先にSELECTを実行して対象を確認して、where句を利用してUPDATE文を作成するようにすることで、間違ったデータを更新してしまう事故を防ぐことが可能でしょう。また、実際の作業で不安な場合は上司や先輩に最終確認をお願いするのも有効な手段の一つです。
データを削除するSQLは「DELETE」です。UPDATEと同じく条件指定を省略すると、すべてのデータが削除対象となります。
ここでは、1件のデータに絞り込んで削除するSQLの例とともに、実行後のテーブルのイメージを紹介します。
| [例] DELETE from m_user where> id = 2; |
|---|
[実行後のテーブルの状態]
| id | name | value |
| 1 | 山田太郎 | 80 |
| 3 | 高橋二郎 | 100 |
| 4 | 田中夏子 | 65 |
「id」が2のデータが削除されています。DELETE文では、「from」で対象テーブルを指定した後、「where」で条件を指定します。
DELETEの削除SQLは、各データに関連した情報などを考慮しつつ、一件ずつ丁寧に削除処理を実行するため、複雑なデータベースの場合は非常に低速となる傾向があります。
テーブル内の全データ削除には、「TRUNCATE」を使用するのが一般的です。TRUNCATEはDDLに分類されるSQLではありますが、テーブル構造に対しての削除となるので非常に高速です。
SQLで扱うデータベースは「RDB(関係データベース)」や「RDBMS(関係データベース管理システム)」と呼ばれます。開発現場などでは「リレーショナルデータベース」とも呼ばれます。
複数のテーブルを関連付ける定義(リレーション)を持たせることで、効率よく複雑なデータを管理できるようになっています。
リレーションには複雑な定義などもありますが、ここでは複数のテーブルを関連付けながら管理するイメージをつかんでいただくために、簡単な例を紹介します。
まずは解説で使用するサンプルのテーブルを定義しておきます。この章では、以下のテーブルがあることを前提として解説を進めます。SQLでできることをイメージしやすく紹介するため、細かな定義などは割愛して、簡略化して表記していることをあらかじめご了承ください。
サンプルテーブルは、テストの点数結果をまとめているようなデータベースをイメージしています。
m_user
| id | user_name |
| 1 | 山田太郎 |
| 2 | 佐藤花子 |
| 3 | 高橋一郎 |
m_subject
| id | sub_name |
| 1 | 国語 |
| 2 | 算数 |
t_data
| id | uid | sid | value |
| 1 | 1 | 1 | 80 |
| 2 | 1 | 2 | 68 |
| 3 | 2 | 1 | 92 |
| 4 | 3 | 1 | 42 |
| 5 | 3 | 2 | 60 |
「m_user」は「ユーザーマスター」のイメージで、管理するユーザーのデータが入っています。ここでは3人のデータを定義しています。
「m_subject」は「教科マスター」のイメージで、国語と算数が定義されています。
「t_data」は「テスト結果」をまとめたトランザクションテーブルで、ユーザーと教科のidとともに、valueでテストの点数を管理しているといった定義になっています。
複数のテーブルでデータが管理されている場合に、同時に並べて一覧を見たい場面は頻繁にあります。
今回の例でデータが蓄積されているテーブル「t_data」には、マスターのidは保存されていますが、そのまま画面に表示されても閲覧者は理解できないため、マスターテーブルから情報の中身を引き出してくる必要があります。
一件ずつマスターテーブルを調べると時間がかかってしまうため、こういう場合には複数のテーブルを連結します。連結する方法の中で最も分かりやすい「LEFT JOIN」について、以下に単純な例を紹介します。
| [例] SELECT * from t_data LEFT JOIN m_user ON t_data.uid = m_user.id; |
|---|
[実行結果]
| t_data.id | uid | sid | value | m_user.id | user_name |
| 1 | 1 | 1 | 80 | 1 | 山田太郎 |
|---|---|---|---|---|---|
| 2 | 1 | 2 | 68 | 1 | 山田太郎 |
| 3 | 2 | 1 | 92 | 2 | 佐藤花子 |
| 4 | 3 | 1 | 42 | 3 | 高橋一郎 |
| 5 | 3 | 2 | 60 | 3 | 高橋一郎 |
実行結果は、「from」で指定した「t_data」テーブルに、「LEFT JOIN」で指定した「m_user」を連結した状態となっています。ユーザーマスターが連結されて、ユーザーの名前が結果の一覧に出ています。
「LEFT JOIN」について、少し詳しくみていきましょう。構文としては以下のような形式になっています。
| [例] SELECT * from テーブル名1 LEFT JOIN テーブル名2 ON 連結条件; |
|---|
「テーブル名1」の指定が、このSQLの主となる目的のデータが蓄積されているテーブルです。「テーブル名2」は、「テーブル名1」に関連した情報を保持しているテーブルで、LEFT JOINに続けて指定して参照用に連結します。
連結条件を指定することで、関連した情報が付与された結果が得られます。今回の例では、ユーザーのIDで関連付けてLEFT JOINしたので、「t_data」の「uid」に対応した形でユーザーマスターのテーブルが連結されています。
実行結果に同じ名前のカラムが存在する場合には、テーブル名をともなった形での指定が必要になるので注意しましょう。
絞り込み条件の指定はwhere句で行いますが、指定の仕方にはさまざまな方法が準備されています。固定の値を指定するだけでなく、他のSQLの実行結果を使うことも可能で、これらを組み合わせることで複雑な抽出を行うことが可能となっています。
最初に、比較演算子としての「in」を紹介します。
| [例] SELECT * from m_user where id in (1,3); |
|---|
[実行結果]
| id | user_name |
| 1 | 山田太郎 |
| 3 | 高橋一郎 |
「in」は複数の値を列挙して指定できます。複数の値の間を「,(カンマ)」で区切って指定します。この例では、「m_user」テーブルの中で、idが1と3のものが抽出されます。
「=(イコール)」の指定では単一の値だけを指定できますが、inを使用すると複数の値を指定できます。inの括弧の中に、値を一つだけ指定することもできるので、とても使い勝手が良い指定方法です。
inを利用して、他のSQLを抽出条件に用いた例を紹介します。今回のテストの結果で70点未満の教科があった人を探し出す場合は、以下のようなSQLが考えられます。
| [例] SELECT * from m_user where id in (SELECT uid from t_data where value < 70); |
|---|
数値で指定していたinの中身がSQLに置き換わっていて、後半のSELECT文でテスト結果70点未満の人のユーザーIDを取得します。後半のSQLだけを実行した場合も確認してみましょう。
| [例] SELECT uid from t_data where value < 70; |
|---|
[実行結果]
| uid |
| 1 |
| 3 |
SELECTで返却されるカラムをuidのみと指定しているため、実行結果には一つのカラムしかありません。このidの抽出結果をSQLの検索条件で使うと、条件で指定したSQLが先に実行されて、その結果が本来のSQLの抽出条件に使用されているイメージです。
|
SELECT * from m_user where id in (SELECT uid from t_data where value < 70); ↓ SELECT * from m_user where id in (先に実行される); ↓ SELECT * from m_user where id in (1,3); |
|---|
SQLでは、単純なデータの挿入や抽出だけでなく、さまざまな機能が使えます。ここでは、その中でも特徴的なものをいくつか紹介します。
データの抽出はSELECT文で実行しますが、その結果を出力する過程でデータベースにさまざまな命令を与えることができます。ここではよく使うことがある集計の機能などを紹介しています。
どのようにSQLを組み立てていくのか、複雑なSQLを実際に作っていきながら、順を追ってその流れを確認してみましょう。
プログラムでデータベースの数値を集計するような機能を作成しなくても、データベースは標準で集計を行う機能をもっています。データベースから取得する段階で集計が行われるため、プログラマーの作業量や処理時間を短縮することができます。
ここでは、ユーザーの合計点を得る例を紹介します。
| [例] SELECT uid, sum(value) as summary from t_data GROUP BY uid; |
|---|
[実行結果]
| uid | summary |
| 1 | 148 |
| 2 | 92 |
| 3 | 102 |
「GROUP BY」は指定したカラムの値でデータをまとめるという指定で、SELECT句の中の「sum」で集計します。GROUP BYでまとめる過程で集計をするイメージです。
「as」は別名の定義をするもので、集計数値は元の値とは別の意味になるため指定してあります。「as」は省略可能ですが、元のカラムと混同してしまうのを避けるため、指定するようにしましょう。
少しおもしろいSQLとして、「UNION」を紹介します。「UNION」は複数の結果を結合して一つの結果とするために使用します。
ユーザー1とユーザー3の教科1(国語)の結果を一覧として表示する例をみてみましょう。
| [例] (SELECT * from t_data where uid = 1 and sid = 1) UNION ALL (SELECT * from t_data where uid = 3 and sid = 1); |
|---|
[実行結果]
| t_data.id | uid | sid | value | m_user.id | user_name |
| 1 | 1 | 1 | 80 | 1 | 山田太郎 |
| 4 | 3 | 1 | 42 | 3 | 高橋一郎 |
単純に複数の「SELECT」を「UNION ALL」でつないであります。今回は同じテーブルからの抽出結果なので、すべてのカラムを対象とする「ALL」が指定してあります。
今回の例は、UNIONを使わず以下のSQLでも同じ結果を得ることができます。
| [例] SELECT * from t_data where sid = 1 and uid in (1,3); |
|---|
単純な例なので簡単に置き換えることができていますが、複雑な抽出結果をひとまとめにしたいときにこそUNIONの真価が発揮されます。基幹システムなどではUNIONを利用して何百行にも渡るSQLを組み立てることもあります。
少し複雑なSQLを組み立てていく流れを確認していってみましょう。SQLは最初から複雑なものを作っていくものではなく、目的のSQLを組み立てていくと、徐々に複雑なものへと肥大化していくものです。
今回は、「高橋」さんのテスト結果を「教科名」「点数」の2項目の形で得ることを考えてみます。
使用するテーブルは単純なものではありますが、教科名は「msubject」にあり、点数は「tdata」にあるので、少なくとも複数のテーブルを連結して取得しなければならないことが分かります。
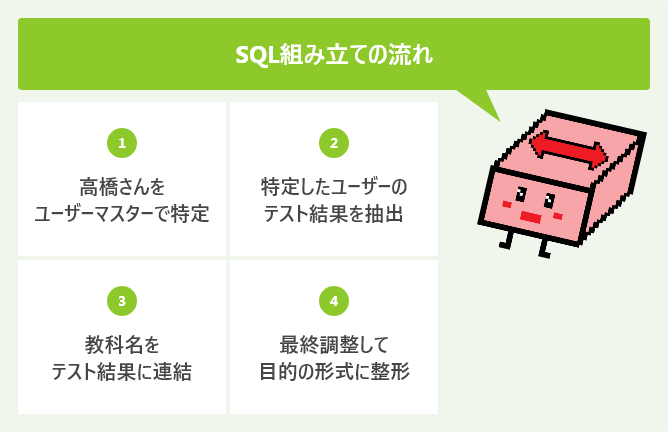
どこから手を付けていいか分からないときは、人間が考えるときのように、順番にSQLを組み立てていきましょう。
まずは「高橋」さんという情報が、データベース上でどういったデータなのかを突き止める必要があるため、最初は「高橋」さんに該当するデータを探すSQLを考えます。
| [例] SELECT id from m_user where user_name like ‘高橋’; |
|---|
[実行結果]
| id |
| 3 |
where句の中に「含む」という意味の「like」が指定されています。また文字列は「’(シングルクォーテーション)」で括って指定します。
今回の例の「高橋」さんは、「m_user」の「user_name」にあることが分かっていますが、名字部分だけなのでデータと完全一致せず「=(イコール)」が使えないため、「like」を用いています。
最終的な出力結果には名前も不要なので、ここではidだけを取得しています。「高橋」さんは、データベース上ではidが3のデータであることが分かりました。
続いて「高橋」さんのテスト結果一覧を得ます。テスト結果は「t_data」にありますが、この抽出条件に「高橋」さんを突き止めたSQLをそのまま利用します。
| [例] SELECT * from t_data where uid in ( SELECT id from m_user where user_name like ‘高橋’; ); |
|---|
[実行結果]
| id | uid | sid | value |
| 4 | 3 | 1 | 42 |
| 5 | 3 | 2 | 60 |
「in」を用いて、「t_data」の中の「高橋」さんすべてを対象にしています。今回の例では「高橋」さんは一人しかいないため、inではなく「=(イコール)」の指定でも可能ではありますが、複数の「高橋」さんがいることを想定してinで指定しています。
「高橋」さんのテスト結果一覧を得ることができて、目的の結果に近づいてきましたが、今回の最終目標には「教科名」と「点数」が必要なので、まだ「教科名」が不足した状態です。
不足している「教科名」の項目は、「m_subject」テーブルにあることが分かっています。同じ実行結果に「教科名」の項目が欲しいため、ここではLEFT JOINを使って連結することにします。
| [例] SELECT * from t_data where uid in ( SELECT id from m_user where user_name like ‘高橋’; ) LEFT JOIN m_subject on t_data.sid = m_subject.id; |
|---|
[実行結果]
| id | uid | sid | value | m_subject.id | sub_name |
|---|---|---|---|---|---|
| 4 | 3 | 1 | 42 | 1 | 国語 |
| 5 | 3 | 2 | 60 | 2 | 算数 |
実行結果の右端に「m_subject」のテーブルが連結されて、必要な情報である「教科名」と「点数」が集まりました。必要な情報は集まっていますが、目的の表には不要な項目が含まれています。
このように、一つ一つは単純なSQLばかりですが、それぞれを条件の指定やLEFT JOINなどの操作に組み合わせていくことで、一つのSQLでありながらも段階を踏んだ処理を構築していきます。
集まったデータを、目的の表形式で得ることができるように、SELECT句を調整します。基本的には必要な項目だけを指定することで、不要な項目を一覧から排除します。
| [例] SELECT m_subject.sub_name, t_data.value from t_data where uid in ( SELECT id from m_user where user_name like ‘高橋’; ) left join m_subject on t_data.sid = m_subject.id; |
|---|
[実行結果]
| sub_name | value |
|---|---|
| 国語 | 42 |
| 算数 | 60 |
SELECT句に「教科名」として「m_subjectテーブル」の「sub_name」と、「点数」としての「t_data」の「value」を指定しています。
これで今回の目的だった「高橋」さんの、「教科名」と「点数」の一覧表が得られました。
最初は最終的にどのようなSQLとなるのか想像ができない場合も、このように徐々に組み立てていくことで目的のSQLに近づいていきます。複雑な仕様や要望などでも、ゆっくり時間をかけて組み立てていくことで、段々と最終的な結果に近づいていくため、とても楽しくてやりがいのある作業といえるでしょう。
SQLを習得することで、データベースに蓄積されたデータを自由に扱うことができるようになってくると、早速仕事などで活用したいと思うものですが、データベースは扱い方を誤ると大変なことになることがあることを忘れてはいけません。
データベースを扱ううえで注意しなければならないことについて、いくつか紹介をします。プログラミングなどでもそうですが、やや回り道のように感じる安全策は普通だと考えて実行できるように癖をつけることが重要です。
Webの検索システムなどでは、ユーザーの入力結果をSQLに使用します。入力された文字をそのままSQLの文字列に連結して使用すると、入力文字にSQLで使う構文が含まれていた場合などに正しいSQLが生成されず、実行に失敗することがあります。その構造を悪用されることで、データが削除されるなどの危険性があります。
このようなセキュリティホールを「SQLインジェクション」と呼び、セキュリティ対策の基本として欠かせません。
対策を施さない実装方法は簡単で習得も容易ですが、実際の開発現場では使用できない場面が多く、できるだけ最初から対策済みの方法を習得して、慣れておきましょう。
データベースに慣れてきたエンジニアは、よく「うっかりミス」をします。データを削除するSQLに必要な条件式をつけ忘れて実行してしまうといったミスでは、すべてのデータが削除されて取り返しがつかない大事故になることもあります。
トランザクションを使うことで、このミスを事前にある程度防ぐことが可能です。
トランザクション機能は、SQLの実行を実際に行うのではなく、仮に実行した結果を見てから適用するかを決定できます。この方法は面倒ではありますが、安全面を考慮して、必ず利用する癖をつけるべきです。テーブルの抽象的な概念としてのトランザクションテーブルとは異なるものなので、混同しないように注意しましょう。
簡単なトランザクションを使用したSQLの例を紹介します。以下の例では、idが2のユーザーの名前を更新しようとしていますが、実行の前後にデータの状況を見るSQLが実行されるようになっています。
| [トランザクションの例] begin — 更新前の確認SQL SELECT * m_user where id = 2; — 目的の更新SQL UPDATE m_user set user_name = ‘鈴木花子’ where id =2; — 更新後の確認SQL SELECT * m_user where id = 2; rollback; |
|---|
[結果]
m_user
| id | user_name |
|---|---|
| 2 | 佐藤花子 |
m_user
| id | user_name |
|---|---|
| 2 | 鈴木花子 |
2つのSelectが実行されたので、結果が2回表示されています。
「begin」によってトランザクションが開始され、「rollback」によってトランザクションを終了して、トランザクション中の出来事をすべてもとに戻すように指定してあります。このトランザクションを用いることによって、データベースへの変更前後を安全に確認できます。
結果を反映する場合は、「rollback」となっている部分を「commit」に変更したSQLを実行します。
しかし、上記例では「update」の「where」を指定し忘れた場合の対策が十分ではありません。確認に指定するSQLには何が正しいのか、何に注意すべきなのかを十分検討してSQLを組み立てましょう。
データベースの設計作業では、目的のデータ管理を実現することに注力してしまいがちですが、初期の設計段階からしっかりと運用後のことも想定しておきましょう。
どのテーブルのデータが蓄積されていくのかを把握して設計に活かすことは、システムの長期運用にともなう速度低下を防止するために非常に重要です。あらかじめデータのライフサイクルを決定したり、仮運用のデータ傾向からインデックスの見直しを行うなど、システムが実運用に入って肥大化する前に、事前にできる対策を行うことは非常に大切です。
こういった長期的な視野を持った設計知識は、書籍などから学習するのが難しく、データベースの開発現場で培われることが多いものなので、上司や先輩などのやり方や考え方から積極的に学ぶように努力しましょう。
SQLを勉強するよりも、プログラミング言語やそのほかの技術を学ぶべきなのではないかと考えることもあるでしょう。確かにSQLが使えるのはデータベースを扱うときだけで、非常に限定的なようにも見えるかもしれません。
ここでは、SQLを習得することで得られるメリットや、逆にSQLならではのデメリットなどを紹介します。それぞれを確認して、自身の目指す道や、勉強の方向性を検討するのに役立ててください。
データベースを扱うシステムは多く存在していて、現在も次々に新しいソフトウェアやアプリが開発され続けています。SQLはそういったシステムの開発や改善などの際に必要となり、利用される頻度が非常に多い言語です。
SQLは、同じ目的であっても異なる解決方法が無限大にあり、工夫が楽しい言語なので、エンジニアの仕事も同様に楽しく作業できるでしょう。
また、データベースを扱うエンジニアは、システムのデータを閲覧できる特権があるともいえ、一般の人が知り得ないさまざまな情報を知ることができます。情報を得ることに楽しみを見出すのも良いですし、その情報をもとに新しいアイデアを思いついて、新サービスの開発に挑戦してみるのもやりがいがあるでしょう。
SQLの一番のデメリットは、データベースだけに特化した言語であって、アプリケーションやソフトウェアを作り出すことができないことです。データベースを扱うシステムの中でも、重要な部分ではあるものの、SQLが占めるのは一部分にしか過ぎません。
また、目に見える動きのあるものを作ることもできず、SQLの担当は必ず地味な部分です。一般の人に見られて賞賛を浴びるのは見た目の部分であることが多く、SQLのようなデータベースに関連した部分は、同業者以外には評価されづらいものです。
そして、地味な部分にもかかわらず、とても重要なデータを扱うことになるため責任は非常に重く、やりがいはあっても、人によってはデメリットと感じる方もいるかもしれません。
IT業界のソフトウェア産業ではデータベースを扱うことが多いため、エンジニア職の多くはデータベースと何かしらの関係を持っています。データベースを扱うことは多くても、すべてのエンジニアがSQLまで駆使してデータを処理しているわけではありません。
ここではSQLを実際に使用しているエンジニアについて紹介しています。SQLを習得してIT業界に入ろうと考えている方は、ぜひ参考にしてみてください。

また、それぞれのエンジニアについて詳しく解説をした記事も合わせて紹介しているので、年収や勉強方法などについて興味がある方は、ぜひそれぞれの記事も合わせてご覧ください。
IT業界のエンジニアとして、非常に知名度のある職種であるプログラマーは、データベースを使うプログラムを作る作業の中で頻繁にSQLを使用します。
画面に関する部分とデータ処理の部分を別々のプログラマーが担当する場合があるなど、現場やプロジェクトによっても業務の割り振りはさまざまで、すべてのプログラマーがSQLを習得しているわけではありませんが、エンジニアの中では使う機会が多い職種になります。
SQLを勉強するとともに、プログラマーとして必要なことも習得すれば、IT企業への就職活動では即戦力として自己アピールできて、大変有利です。
関連記事:プログラマーとは|仕事内容や年収から向いている人や資格まとめ
データベースに特化したエンジニアとして、データベースエンジニアというITスペシャリスト職があります。プログラマーからキャリアアップしてなっている人も多く、SQLに関する知識や経験が多く備わっている人が多い職種です。
プログラマーよりも、データベースの設計や構築といった上流工程を担当することが多いですが、プロジェクトによってはデータベースを扱うプログラムの実装やSQLの作成を担当することもあります。
単純に機能を満たすための知識ではなく、セキュリティやネットワークについてなど、幅広い広い知識が求められる傾向にあり、責任も重大ですが、やりがいもあり給与も多くもらえる可能性があるため、SQLを習得した先の目標として目指しましょう。
関連記事:データベースエンジニアとは|仕事内容から必要なスキルまで徹底解説
ソフトウェア開発の現場で多くの経験を積み、システムエンジニアやプロジェクトリーダーといった役割になった人達も、SQLを扱うことがあります。
データベースに関する部分で問題が発生した際などには、SQLを使用して状況を確認します。基本的には担当エンジニアが行うことが多いのですが、SQLの知識があるプロジェクトリーダーやシステムエンジニアは時間の短縮や原因の最終確認などを目的に、自身でSQLを使用して作業を行うこともあります。
これらの職種では、SQLだけに関わらず幅広い知識が求められますが、多くの人たちと新しいものを生み出していく非常にやりがいのある仕事です。データベースだけに留まらず、IT業界で飛躍していくため、積極的に多くのことに興味を持つようにしましょう。
関連記事:IT業界の花形 システムエンジニア | 仕事内容から年収まで解説
プロジェクトマネージャー| 仕事・年収から役立つ資格まで解説!
これからSQLを習得してエンジニアを目指そうと考えられている方々に向けて、簡単なアドバイスを4つ紹介します。
エンジニアを目指すための勉強方法だったり、実際の採用試験においての注意事項など、エンジニアになる過程において役立つ情報ばかりなので、ぜひ参考にしてみてください。

エンジニア採用では特に面接試験が重要です。現在の知識や能力のアピールだけでなく、自身の技術への関心の高さや、習得への取り組み姿勢など、前向きな考え方を積極的に示しましょう。
データベースを扱うシステムを抱えている企業は多く、SQLが得意な人はエンジニア採用では有利です。IT業界にはSQLができる人が多くいるので、自分自身がどのくらいの実力なのか、具体的にアピールできた方が良いでしょう。個人での学習ももちろん重要ですが、実績があると非常に強いです。
転職の場合は前職で関わったプロジェクトなどをできる範囲で提示することで、自分が担当した作業や問題への対処方法などに興味を持ってもらい、評価されることになるでしょう。
一見SQLとは関係なさそうに思えるかもしれませんが、Linuxにも知識があると心強いです。
データベースエンジニアは、データベースの定期的なバックアップやセキュリティ権限の設定など、OSの機能と隣り合わせの作業も多く行うため、Linux操作に慣れている必要があります。特に上流の工程では頻繁にLinuxを活用することになるでしょう。
規模が小さなプロジェクトなどでは、プログラマーもデータベースの構築などまで担当することになり、Linuxを操作する機会は多くあります。SQLとともにLinuxについての知識があることは、まさに鬼に金棒といえる状態なので、ぜひ興味を持って習得していきましょう。
Linuxについて詳しく知りたい方は、以下の記事で詳しく紹介しているので、ぜひそちらもご覧ください。
関連記事:Linux(リナックス)って何|意味や用途を完全解説
これからデータベースやSQLの勉強を始めようという方には、Linux環境で動くデータベースをオススメします。
WindowsデータベースであるSQL Serverは、WindowsというOSでしか動作しませんが、そのほかのデータベースの多くはWindowやLinux両方で動くことが多いため、SQL Server以外のデータベースと出会う確率の方が高い傾向にあります。
SQL Serverは操作が容易なWindowsでもあり、先にLinuxのデータベースを習得していれば、比較的短時間で習得も可能です。逆のパターンでは大変な思いをすることになるので、選択ができるのであれば、Linuxと何かのデータベースを組み合わせた環境で勉強を始めていきましょう。
データベースやプログラミングに集中すると、ネットワークやセキュリティについてまで勉強する時間を取れないことも多いでしょう。しかし、これらの分野について興味を持っていることは非常に重要な要素です。特に、データベースはほとんどの場合インターネットなどのネットワーク上で動くことになるので、避けて通ることはできない分野です。
まったく異なる技術知識ばかりではありますが、これらの分野にある程度の知識が備わっていることは採用でも有利に働きます。さらに、その分野に対して抵抗感がなく、興味を持って取り組みができるエンジニアは、多方面での活躍が期待され、将来性を高く評価されるでしょう。
ネットワークに関して基礎的な知識があることをアピールできるCCNAといった資格を持っていることも、採用で有利に働く可能性があるので、取得を検討してみることをお勧めします。CCNA試験について詳しく知りたい方は、ぜひ以下の記事もご覧ください。
関連記事:CCNAとは|試験の難易度から合格するための勉強方法まで紹介
SQLを習得する過程は、徐々に大きく複雑なことができるようになっていくため、楽しく進めることができます。SQLが得意になると、エンジニアとしても幅広い分野の仕事に関わることができて、有利になることも多くなります。
少しでも速く結果を出せるSQLを組み立てることができると、驚くほどの達成感も味わえ、速いSQLは、多くの利用者や社会に役立てることができます。
効率の良いデータベースシステムを構築できるように、SQLを習得しましょう。
あなたにはどれが向いてる? 今すぐエンジニア診断してみよう

「エンジニアになってIT業界で働きたい」
「エンジニアに興味はあるけど、種類が多すぎて自分に向いてる職種がわからない」
そんな悩みを解決するのが、「エンジニア診断ツール」です。
「エンジニア診断」はたった12の質問に答えるだけで、あなたに向いているエンジニアを診断。
診断結果には仕事内容の概要も掲載しているので、自分に合ったエンジニアについて詳しく知って、エンジニア就職に一歩近づきましょう。
飯塚 寛也
2022.04.27

2022.01.24

2022.01.12

2020.09.09

2020.07.03

2020.06.19

2020.06.11

2020.06.04




